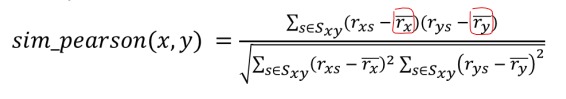iNut
Da se nadovežem na ovo svoje, naravno da je problem bio kao što je kolegica gori navela i kao što su mnogi drugi naveli u labosu od prošle godine, pisao sam u Pythonu. Za listu sličnosti sam koristio list comprehension kojemu su elementi bili parovi (cosine(x, y), indeks usera/itema) a ta je lista bila složena tako da sam unutar list comprehensiona to sve stavio unutar sorted funkcije te joj predao zastavicu reverse=True da bi mi ispisalo po opadajućoj vrijednosti sličnosti da mogu odmah izbaciti element sa sličnošću 1.0 (to je taj za kojeg tražimo rejting) te bi se element dodao ako je sličnost veća od nule.
Sljedeće sam provjeravao po listi po elementima indekse te sam gledao u originalnoj matrici koje ocjene user nije dao odnosno item ih nema (ovisno o pristupu).
Na kraju sam ispisao predviđanje.
Moja pogreška:
Napravio sam sve kako sam rekao za inicijalnu listu sličnosti, no nisam izbacio elemente koji nemaju ocjenu za promatranog usera/itema nego sam prvo uzeo prvih K vrijednosti (pošto su najveće) pa sam ih onda izbacivao.
Dakle klasična greška za ovaj labos. Dico čuvajte si živce i poštedite nepoznate kolege koje uče s vama na hodniku vaših psovki na glas.