Pepper
Settao sam mu 18 -> 8 (max broj bodova) jer se vjerojatno radi o grešci prilikom upisa. -3 sam settao na 3 vodeći se istom logikom (plus ne postoje negativni bodovi). Overkill: napraviti multivarijatnu imputaciju za ta 2 podatka
Ducky
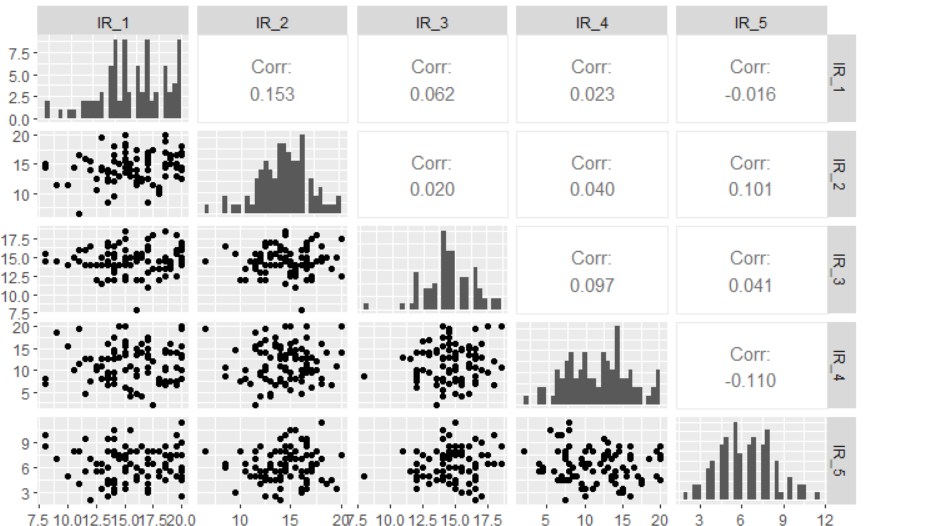
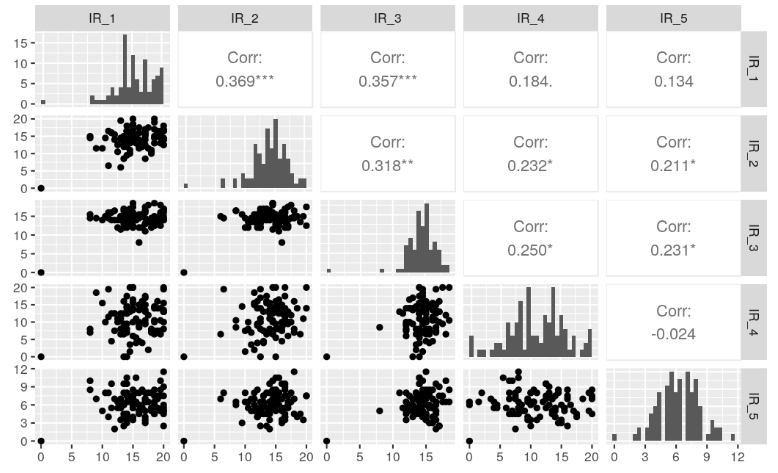
Pronađi neku od statističkih udaljenosti (mahalanobis-ovu) za sve primjere. S tim udaljenostima provedi chi kvadrat test i pronađi primjere čija je udaljenost od drugih primjera statistički značajna (npr. za alpha = 0.01)
sheriffHorsey
kako bi ja onda trebao micat NA podatke na razini cijelog dataseta? vise mi smisla ima filtrirat u kasnijim podzadacima kad me se pita da radim samo na podacima s roka/kontinuirano
komentar na ovo što je Dragi prijatelj strojnog učenja rekao; nije bitno s kojom vrijednošću zamjeniš NA-ove za IR_{1,2,3,4,5} dokle god kasnije filtiriraš studente koji su uistinu išli na IR (npr. sa varijablom otisao_na_ir 0/1) kad radiš analizu koje sadrže varijable IR_{1,2,3,4,5}. NA-ovi kod IR_{1,2,3,4,5} mogu se zamjeniti sa 0, mean, multivarijatnom imputacijom (ovo je možda fora ako želiš brzo vidjeti kakve bi bodove dobili studenti na IR-u a da nisu išli na IR)