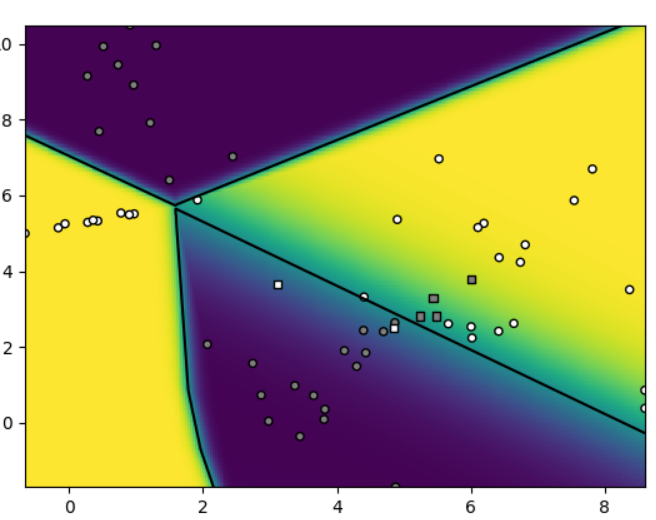
Usporedite performansu modela koje implementiraju razredi PTDeep i KSVMWrap na većem broju slučajnih skupova podataka. Koje su prednosti i nedostatci njihovih funkcija gubitka? Koji od dvaju postupaka daje bolju garantiranu performansu? Koji od postupaka može primiti veći broj parametara? Koji bi od postupaka bio prikladniji za 2D podatke uzorkovane iz mješavine Gaussovi distribucija?
Jel bi mogao netko malo pojasniti ovu usporedbu? PTDeep se cini dosta sporiji jer ima vise parametara, al koji bi bio prikladniji za 2D distribuciju i zasto?