Challenge accepted, nek netko nađe odgovor na 8. ja nemam pojma
Ukupan broj poruka koje se razmijene (pošalju) u provedbi komunikacijske strukture binarnog stabla za 2D procesora iznosi 2d - 1_.
Kompozicija modula u paralelnim programima može biti ___ Serijska, paralelna i zajednička kompozicija ___.
Ako je učinkovitost 25%, a ubrzanje je 4, koliki je broj procesora? 16? (S=P*E – S=ubrzanje, E=učinkovitost pa onda P=S/E tj 4/0.25 = 16)_________.
Izoučinkovitost opisuje kako se mora promijeniti br procesora u ovisnosti o količini posla (računanja) kako bi _učinkovitost ostala nepromijenjena.
Pridruživanje se provodi ukoliko je broj zadataka veći od broja procesora.
Na APRAM računalu, unutar istog asinkronog odsječka, samo _jedan procesor smije pristupiti istoj globalnoj memorijskoj lokaciji.
Koje dodatne parametre uvodi model APRAM u odnosu na model PRAM? __ B (vrijeme potrebno za sinkronizaciju p procesora) i d – vrijeme za globalno čitanje/pisanje __.
Ukupan broj poruka koji se razmjene(pošalju) u provedbi komunikacijske strukture hiperkocke za 2d procesa iznosi______??.
Povecanje zrnatosti može se postici tehnikama __Povećanje zadataka, uvišestručavanje računanja __.
Ako je ubrzanje linearno, ucinkovitost je(kakvog iznosa?) jednaka 1_.
Ako je superlinearno učinkovitost je veća od 1
Ako je sublinearno učinkovitost je manja od 1
Uz superlinearno ubrzanje, učinkovitost je (kakvog iznosa?) >1.
Navedite sve četiri vrste aPRAM instrukcija: Globalno čitanje, Globalno pisanje, Lokalna operacija, __Sinkronizacija / ograda.
Funkcija izoučinkovitnosti opisuje kako se mora promjeniti količina posla_ u ovisnosti o promjeni broja procesora kako bi ___učinkovitost___ ostala nepromijenjena.
Faza pridruživanja se provodi ukoliko je broj Zadataka veći od broja _procesora___.
Uvišestručavanje računanja je tehnika kojom se povećava ukupna količina računanja kako bi se smanjila količina komunikacije.
Pojava zagušenja voditelja u modelu voditelj-radnik moguća je uz prevelik broj radnika.
Ukoliko se ubrzanje paralelnog programa mjeri u odnosu na najbolji slijedni program, radi se o apsolutnom ubrzanju.
Ukoliko se ubrzanje paralelnog programa mjeri u odnosu na isti program pokrenut na jednom procesoru, radi se o relativnom ubrzanju.
MPI mehanizam dijeljenja komunikatora omogućava izvedbu paralelne kompozicije modula u paralelnom programu.
MPI mehanizam modula u paralelnim programima omogućava izvedbu slijedne i paralelne kompozicije modula_.
Ubrzanje veće od linearnog naziva se superlinearno.
Povećanje zrnatosti možemo ostvariti tehnikama: _Povećanja zadataka i uvišestručavanja računanja_.
Prilikom istodobnog čitanja iste memorijske lokacije u CRCW PRAM računalu, svaki procesor će pročitati istu/jednaku vrijednost.
Izraz koji opisuje trajanje slanja jedne poruke duljine L riječi u jednostavnom modelu komunikacije je: _Tmsg = ts + twL (ts - postavljanje poruke, tw - prijenos jedne riječi).
Zrnatost zadataka se može definirati kao količine računanja (lokalnog rada) i količine komunikacije (nelokalnog rada)_.
U modelu raspodijeljene memorije, procesori mogu komunicirati jedino razmjenom poruka.
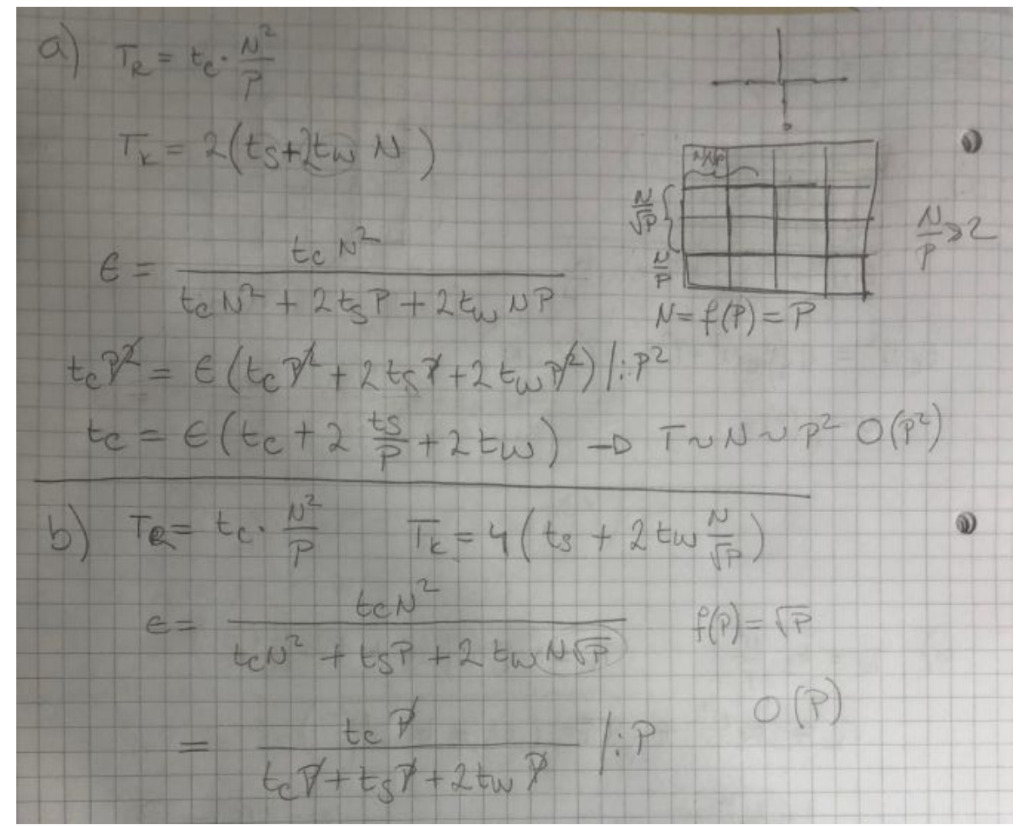
Složenost provedbe postupka scan niza duljine n elemenata na PRAM računalu uz p procesora gdje je p<(n/2) iznosi O(n/p + log p).
Prilikom izvođenja optimalno postupka +_reduciranja niza duljine n na PRAM računalu, ukupan broj operacija zbrajanja na svim procesorima iznosi n-1.
Na APRAM računalu, uz trajanje globalnog pristupa 4 vremenske jedinice, 2 uzastopna globalna pristupa trajat će 5 (4+21 tj (d+k 1)).
Prilikom prilagodbe PRAM algoritma za APRAM računalo uz (p/B) procesora, gdje jedan APRAM procesor izvodi instrukcije za B PRAM procesora, jedna EREW PRAM instrukcija izvodi se u 5B+2d2 koraka.
Optimalna složenost algoritma reduciranja niza duljine n na APRAM računalu uz n procesora iznosi O(B log n) ili O(logBn) (pomoću Barnog umjesto binarnog stabla)_.
Algoritam scan se odnosi na bilo koju binarnu asocijativnu operaciju.
Poželjna svojstva paralelnih programa su istodobnost, skalabilnost, lokalnost i modularnost.
Vrste instrukcija na APRAM računalu su: globalno čitanje, globalno pisanje, lokalna operacija i sinkronizacija____.
Na APRAM računalu, uz trajanje globalnog pristupa 3 vremenske jedinice, 4 uzastopna globalna pristupa trajat će 6 (3+41 tj (d+k 1)).
Amdahlov zakon definira iznos najvećeg mogućeg ubrzanja u ovisnosti o dijelu programa koji se može paralelizirati_.
Vremenska složenost provedbe postupka scan niza duljine n elemenata na PRAM računalu uz p procesora gdje je 𝑝 < 𝑛/2, iznosi ______ O(n/p + log p) _____.
Povratak iz blokirajuće MPI funkcije znači: da je funkcija završila i može se pristupati memorijskoj lokaciji.
Povratak iz neblokirajuće MPI funkcije znači: _da se može ponovno pristupiti toj memorijskoj lokaciji, ali ne i da je funkcija uspješno izvršena – to se mora naknadno provjeriti_____.
Navedite moguce uzroke neslaganja (nepotpunosti) jednostavnog modela trajanja paralelnog programa u usporedbi sa stvarnom izvedbom programa: Nejednako opterećenje, uvišestručeno računanje, nesklad algoritma i programskog alata, ograničen kapacitet komnunikacije
Navedite i moguce uzroke “anomalije ubrzanja” _Upotreba priručne memorije (cache-a) i anomalija pretraživanja
Navedite sve podjele komunikacije u paralelnim algoritmima Lokalna i globalna komunkacija
Navedite moguće nedostatke jednostavnog modela ocjene perfomansi u opisu stvarnog ponašanja paralelnog programa? Jednostavni model ne uzima u obzir ograničenja bandwidth-a komunkacijskog kanala, nejednako opterećene, uvišestručeno računanje, nesklad algoritma i programskog alata
Ako su ostali parametri isti i povećavamo br procesora učinkovitost monotono pada, a ubrzanje raste do neke točka pa nakon tog pada