[obrisani korisnik]
Evo wall of text struje svijesti, nadam se da pomogne.
Prije svega, važno je shvatiti što se događa sa sigmoidom ako množiš njen ulaz sa faktorom alpha. Što više raste faktor alpha, to sigmoida postaje strmija ( 6. cjeline, str 2).
Sljedeće, potrebno je razumjeti da kada koristiš sigmoidu u logističkoj regresiji
\sigma(w^Tx)
wT je ista stvar kao faktor alpha. Kako je on veći, to je sigmoida strmija.
Dalje je potrebno razumjeti gubitak unakrsne entropije. On kažnjava i ispravno i neispravno klasificirane primjere i raste proporcionalno s razlikom izlaza modela i stvarne oznake primjera, tj. |y - h \left(\mathbf{x}\right)|
(vidi cjelinu 6, str 7.)
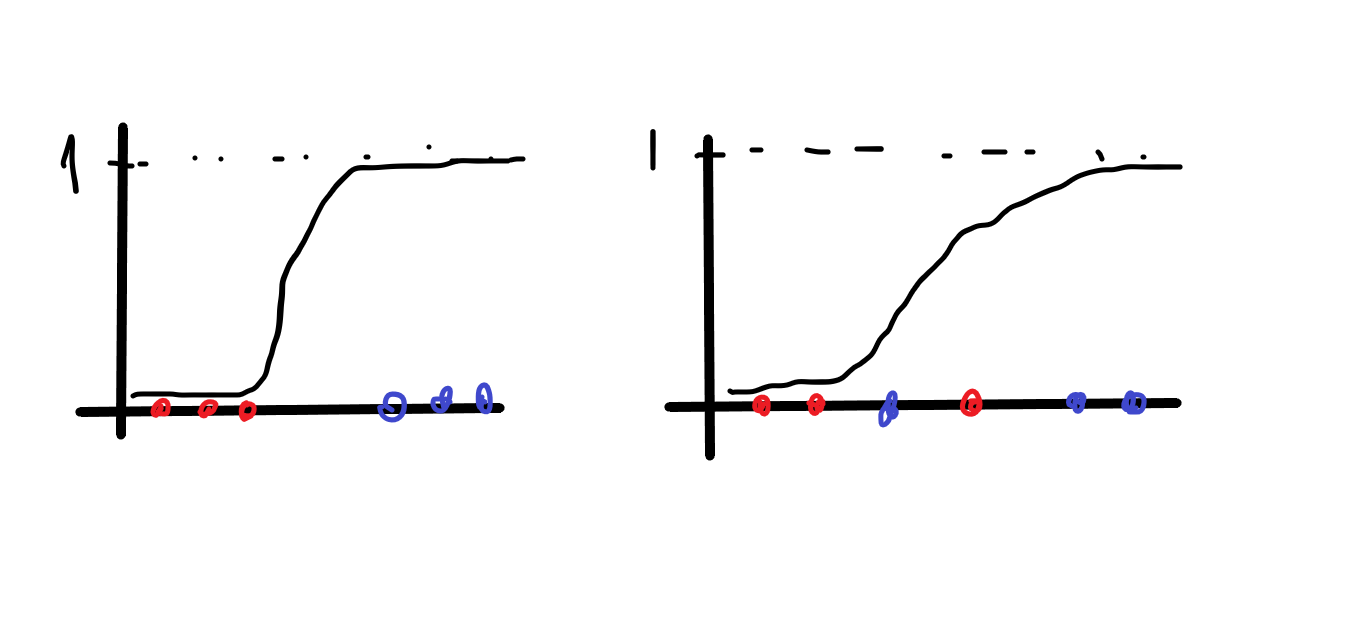
Ajmo sada pogledati što se događa s modelom koji već ispravno klasificira sve primjere. Dakle, primjeri su linearno odvojivi. Zašto on u daljnjoj optimizaciji nastavlja za neki faktor povećavati težine? Zato jer time ne mjenja granicu klasifikacije, a sigmoida postaje strmija. A kad sigmoida postane strmija, izlaz modela za sve pozitivne primjere pomakne se bliže 1, a za negativne bliže 0. Time se smanjuje gubitak, odnosno pogreška, a to je upravo ono što algoritam i želi.
E sad, ako primjeri nisu linearno odvojivi, logička regresija neke primjere neće moći ispravno klasificirati. I sad zamisli da kreneš povećavati težine isto kao i gore. Opet bi sigmoida postala strma i davala vrijednosti blizu ili 0 ili 1. I sad recimo da postoji pozitivno označen primjer na pogrešnoj strani klasifikacijske granice. Za njega bi model dao h \left(\mathbf{x}\right) \approx 0 , što je potpuno krivo klasificirano i gubitak je velik, odnosno gubitak netočno klasificiranih primjera raste što je sigmoida strmija. U drugu ruku, pogreška za sve ispravno klasificirane primjere bi padala. Dakle kako mjenjaš strminu sigmoide, ispravno klasificiranim primjerima gubitak se smanjuje, a neispravnim se povećava.
Poanta cijele priče je da kod linearno odvojih primjera funkciju pogreške uvijek možeš natjerati da teži u nula, a to postižeš jako strmom sigmoidom. Kod primjera koji nisu linearno odvojivi to ne možeš jer minimum funkcije pogreške nije 0 i težine nikad neće rasti nekontrolirano.