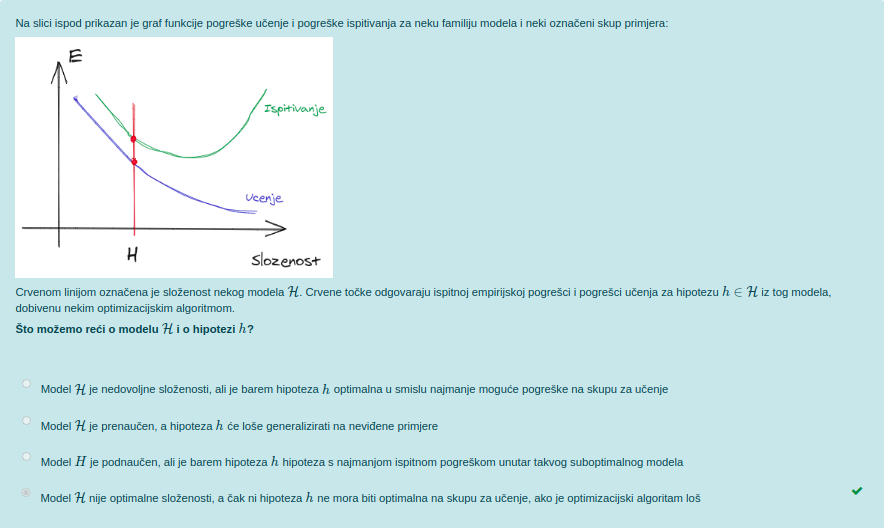
Emma63194 ma taj je lagani kjut zadatak haha
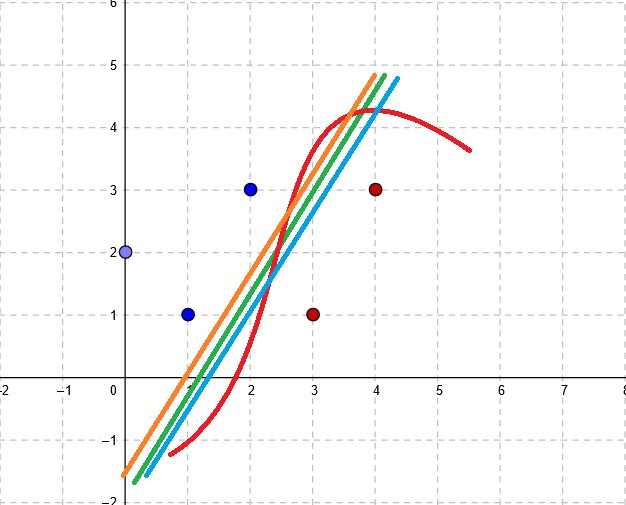
Prvo krenimo od dataseta koji je generiran onom Gaussovom razdiobom, onaj izraz ti je pravac kojeg bi kao trebala dobit da ti je loss funkcija dobra, to je stvarni pravac
No, nemas dobru loss funkciju.
Doduse, fear not, jer ako se samo malo algebarski poigras, (y + h(x))2 = (y - (-h(x))2, odnosno, efektivno ucis nad podacima koji su flipani oko x osi.
(Alternativno, loss ti moze biti i (h(x) - (-y))2 gdje se bolje vidi da y mjenja predznak. Razmisli zasto)
E sad ostavljam tebi za vjezbu da nades jednazbu pravca koji nastane flipanjem ovog zadanog u Gaussovoj oko x osi
Edit: nisam objasnio odakle tezine, pliz napravi korespondenciju izmedu tog kak ti izgleda hipoteza i kak ti izgleda pravac, i trebala bi moci matchat iz tog sta ti je w0 a sta w1