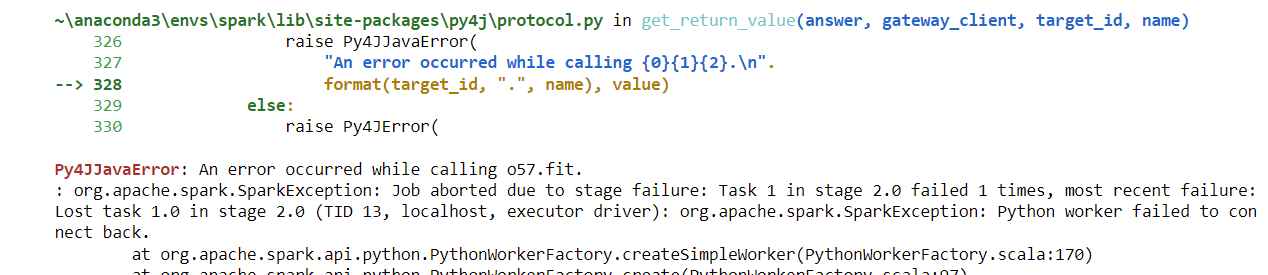
vuk172 Meni je možda malo sporije al ne toliko. A za 6. ja ne koristim vector assembler nego onako kako je u 2., to mi nekak ima više smisla? A i manje je zahtjevno lol
prx_xD
sc = SparkContext.getOrCreate()
rdd_train = sc.parallelize(train)
rdd_test = sc.parallelize(test) -> train i test su meni liste at this point
Smolaa Obradiš liniju po liniju i u neku listu spremiš (id, text, label) i onda tu listu predaš u parallelize ovako kako sam gore napisala
Disklejmer ovo je sve onak kak sam ja radila, ne mora nužno bit 100% točno al eto meni daje convincing metrike pa