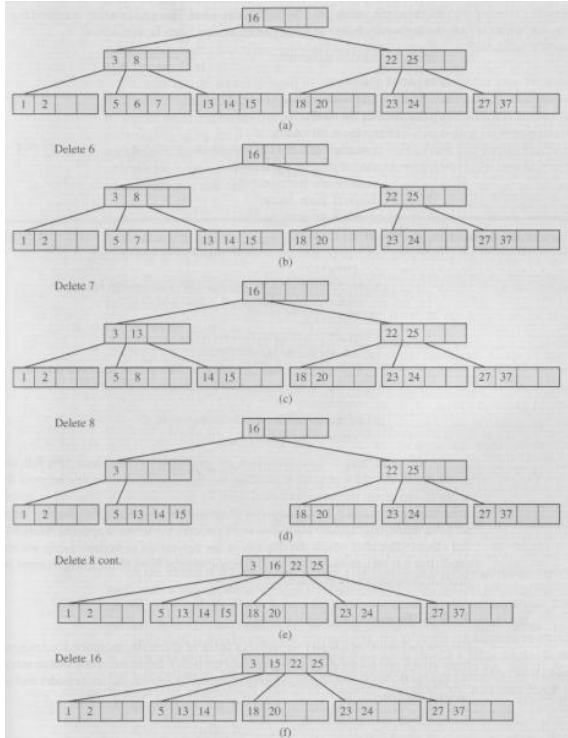
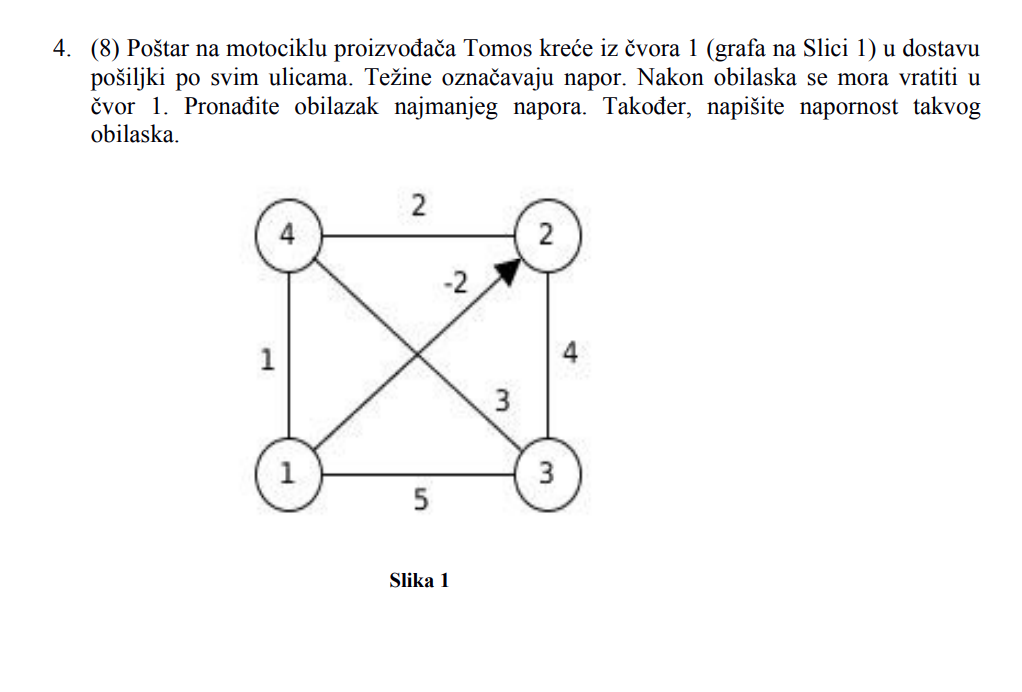
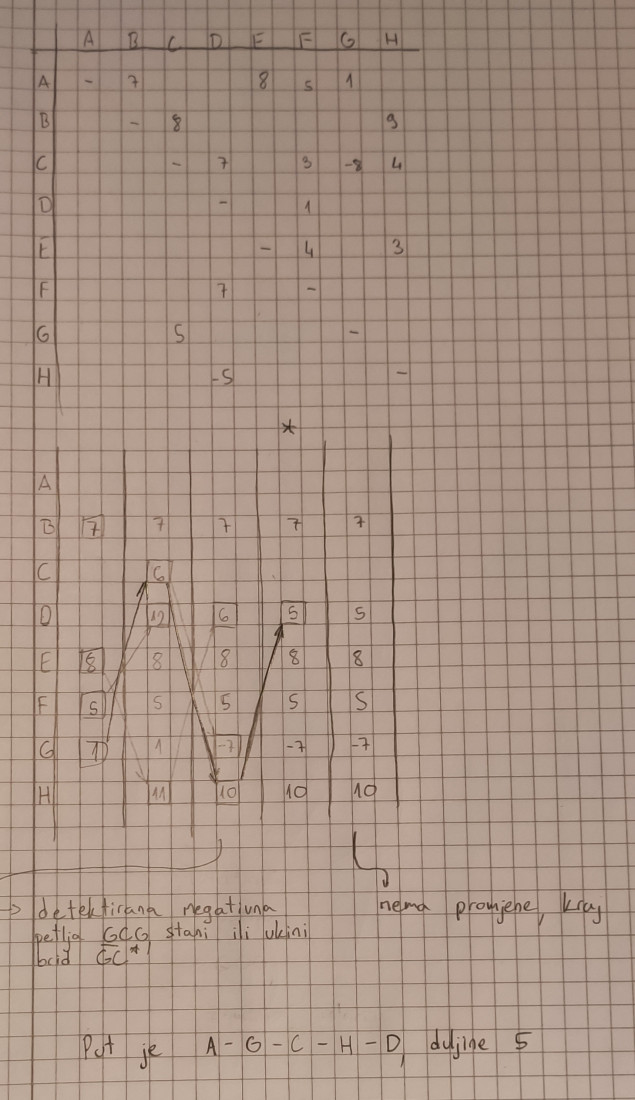
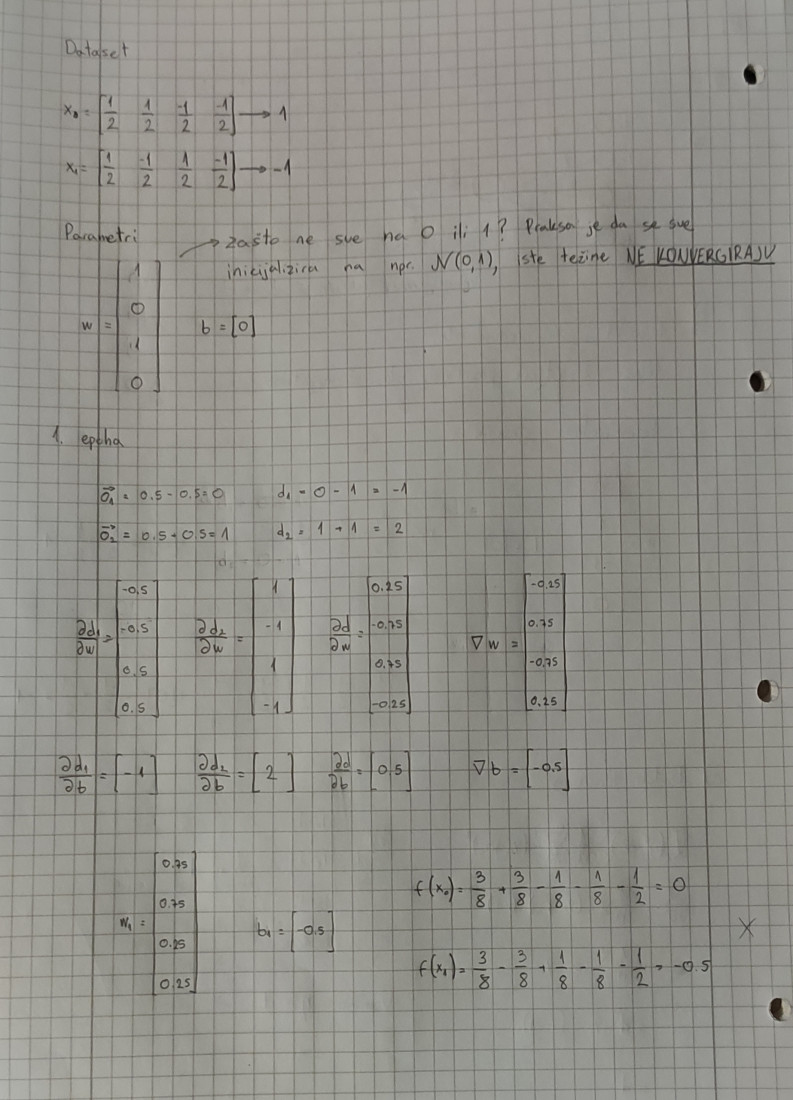
TentationeM Riješit ću to danas, al ovdje imamo problem što nije definirano početno stanje.
Sve što se događa je da akumuliraš gradijent oba ulaza i onda to primijeniš na težine. Odabir težina za 1. i 4. značajku je nebitan (vidljivo je iz ulaza da su redundantne), a težine za 2. i 3. značajku bi inicijalizirao na 1 (radi jednostavnosti), a pomake na 0.
Dakle,
w =
\begin{bmatrix}
0 \\
1 \\
1 \\
0 \\
\end{bmatrix},
b =
\begin{bmatrix}
1
\end{bmatrix}
Uzmite u obzir da su meni ulazi retčani, a ne stupčasti vektor, pa su ove veličine potencijalno transponirane. Gradijent je također elementaran - ako pretpostavimo da koristimo MSE, onda je gradijent izlaza \vec{o} - \vec{y}, gdje o pretpostavlja izlaz mreže a y labelu, nazovimo taj vektor \vec{d}, pa su gradijenti po parametrima
\frac{\partial{L}}{\partial{w}} =
\begin{bmatrix}
i_0 \cdot \vec{d} \\
i_1 \cdot \vec{d} \\
i_2 \cdot \vec{d} \\
i_3 \cdot \vec{d} \\
\end{bmatrix},
\frac{\partial{L}}{\partial{b}} =
\begin{bmatrix}
\vec{d}
\end{bmatrix}
Mislim da uz stopu učenja 0.1 ovo sigurno konvergira, pa se može uzeti ili ta stopa učenja, ili 0.5 koji linearno decaya za 0.1 po epohi. Dodatno: U slučaju batch learninga na malom datasetu može i veći learning rate, npr. 1.
Konkretan postupak, kao i ispravke ću kasnije priložiti, jer trebam još jednom proći to gradivo pa idem na rješavanje zadataka, a na poslu sam trenutno. Ali sve što treba ovdje je računati isto kao on-line learning, akumulirati gradijente, i tek nakon što se prođe kroz cijeli dataset njihov prosjek oduzeti težinama.