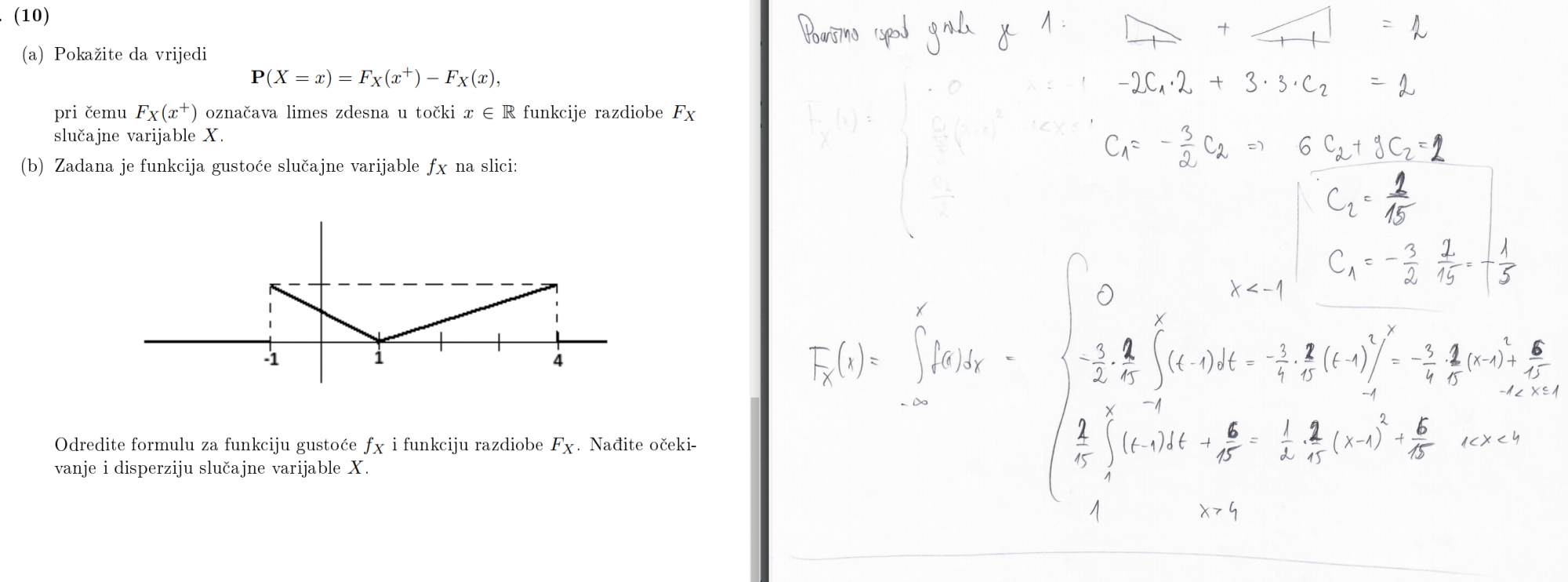
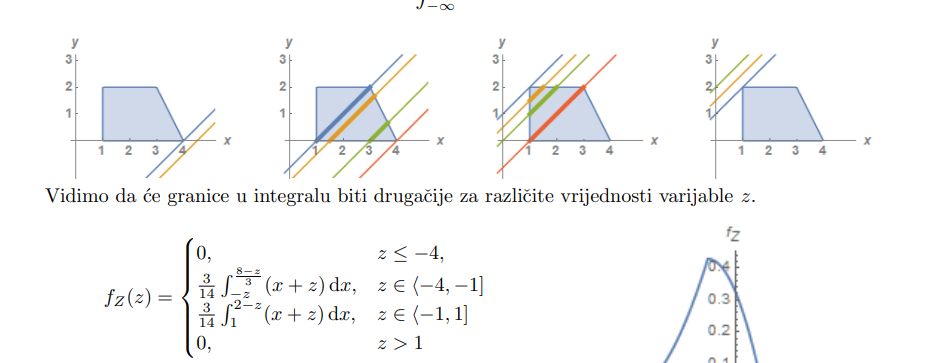
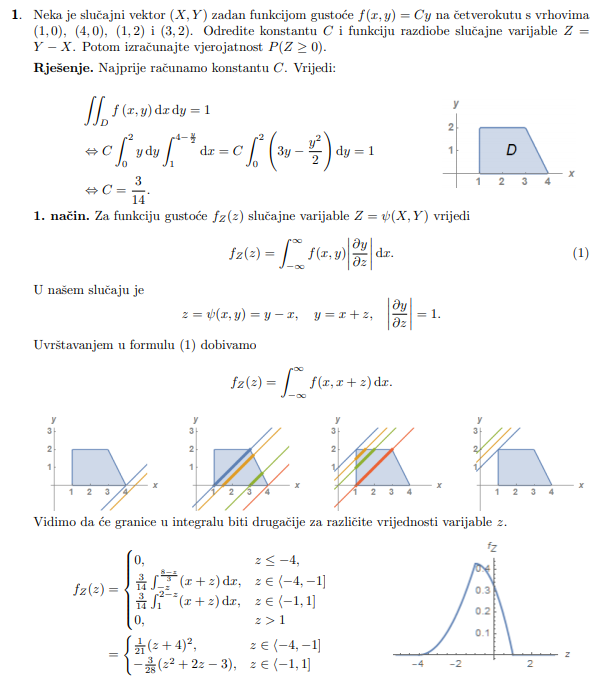
DazedAndConfused centralni granični teorem.
Broj dječaka od n novorođene djece neka bude slučajna varijabla X.
Očito je da X ima binomnu razdiobu (svaki pokus neka je rođenje djeteta, a uspjeh je ako je dijete dečko lmao), dakle
X \sim \mathscr{B}\left(n, p\right), gdje su parametri n = 100 i p = 0.515.
Sad, tražena vjerojatnost P\left(50 \leq X \leq 55\right) bi se egzaktno računala na sljedeći način:
P\left(50 \leq X \leq 55\right) = \sum_{k=50}^{55} \binom{n}{k} p^k (1-p)^{n-k} = \sum_{k=50}^{55} \binom{100}{k} 0.515^k 0.485^{100-k}
Ali to najčešće nije lako računati ručno. Kao prvo ovi povrsi su muka isusova kad su veliki brojevi, a i broj članova sume zna biti dosta velik (u našem slučaju je samo 6 članova, ali što da je zadatak tražio da bude npr. manje od 40 dječaka, ili da je n veći…).
Zato to nije poanta, nego je poanta aproksimirati ovu binomnu razdiobu, koristeći centralni granični teorem, sa normalnom, koja će nam olakšati računanje tražene vjerojatnosti.
Kako se ta aproksimacija radi u slučaju binomne razdiobe i zašto to možemo?
Radi se tako da, kao parametre aproksimirane normalne, staviš očekivanje i varijancu od binomne.
Za binomnu znamo da su očekivanje i varijanca (to se lako pokaže iz definicija očekivanja i varijance):
\mathbb{E} \left(X\right) = \mu = np
\operatorname{Var}\left(X\right) = \sigma^2 = np(1-p)
Prema tome, našu binomnu slučajnu varijablu X ćemo aproksimirati kao
X \sim \mathscr{B}\left(n, p\right) \approx \mathscr{N} \left(\mu, \sigma^2\right) = \mathscr{N} \left(np, np(1-p)\right)
Odnosno kada uvrstimo vrijednosti parametara n i p:
X \approx \mathscr{N}\left(51.5, 24.9775\right).
Zašto to možemo napraviti?
Pa znamo da centralni granični teorem aproksimira sumu n nezavisnih, identično distribuiranih slučajnih varijabli. Kakve to veze ima sa binomnom? Pa ima jer se binomna može prikazati kao suma n nezavisnih Bernoullijevih (indikatorskih) slučajnih varijabli I(p) = \begin{pmatrix}
0 & 1\\
1-p & p
\end{pmatrix}, pa zato centralni granični teorem može aproksimirati binomnu. Aproksimacija je dobra kada n \to +\infty i kada je p blizu \frac{1}{2} (što u našem slučaju jest). Ako p \to 0, tada se koristi zakon rijetkih događaja koji u tom slučaju binomnu aproksimira Poissonovom.
Zašto aproksimirati normalnom? Pa zato što računanje tražene vjerojatnosti, P\left(50 \leq X \leq 55\right), postaje jako lagano (šablona).
A šablona jest: slučajnu varijablu X, sada normalnu, centriraj i normiraj (oduzmi očekivanje i podijeli sa standardnom devijacijom), nazovimo to slučajnom varijablom Y = \frac{X - \mu}{\sigma} koja je tada jedinična normalna slučajna varijabla.
P\left(50 \leq X \leq 55\right) = P\left(\frac{50 - \mu}{\sigma} \leq \frac{X - \mu}{\sigma} \leq \frac{55 - \mu}{\sigma}\right) = P\left(\frac{50 - 51.5}{\sqrt{24.9775}} \leq Y \leq \frac{55 - 51.5}{\sqrt{24.9775}}\right) = P\left(-0.300 \leq Y \leq 0.700\right)
A ovo možeš računati sa onom funkcijom \Phi^*(x) (koja je neparna, a to nam treba jer one tabelirane vrijednosti iz udžbenika su napravljene za pozitivne argumente):
P\left(-0.300 \leq Y \leq 0.700\right) = \frac{1}{2}\left(\Phi^*(0.700) - \Phi^*(-0.300)\right) = \frac{1}{2}\left(\Phi^*(0.700) + \Phi^*(0.300)\right) = \frac{1}{2}\left(0.51607 + 0.23582\right) =0.3759
Zašto je ovo ispalo za nekoliko stotinka različito od rješenja u udžbeniku?
Zato što nisam koristio korekciju na kontinuiranost, a ona se ne traži na kolegiju, i ovo rješenje bi ti donijelo sve bodove na ispitu. Ako se ipak napravi ta korekcija, onda je tražena vjerojatnost, nakon aproksimacije normalnom, P\left(49.5 \leq X \leq 55.5\right), i kada bismo to išli računati dobili bismo 0.4437370184.
I u krajnjoj liniji ako gledamo egzaktno rješenje (vjerojatnost izračunata sa onom sumom na početku sa binomnom), ono je 0.4437657153, pa možeš vidjeti da je greška aproksimacije binomne normalnom zapravo zanemariva ako su parametri povoljni (veliki n i p blizu \frac{1}{2})